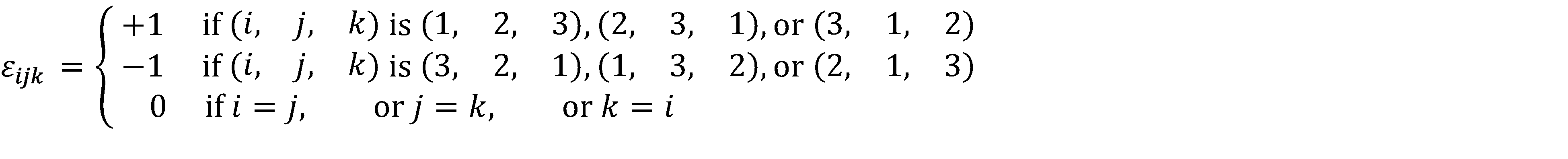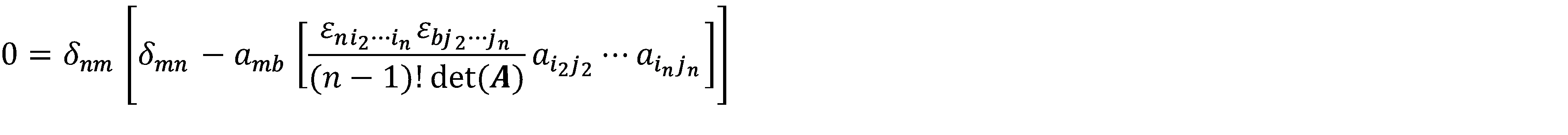This morning’s briefer couldn’t have been more direct. The mission was to hold at risk one of three ballistic missile submarines now at sea and destroy it if necessary. The strategic situation was the result of pressures that had built up since Deng Xiaoping led the Peoples’ Republic to market reforms. Many oligarchs had much to lose, especially those of the PLAN. They recently toppled Xi Jinping and most of his hand-picked Politburo members. The usurpers then went on the offensive regionally to distract attention from their internal power consolidations. Peace talks were underway in Geneva.
The strike flight leader, Major Cole, and his copilot, Captain Work, took off from Whiteman AFB in an B-42, a long-range, arsenal craft. The flight repeatedly refueled and acquired assets in its transit from Missouri to the OPAREA just inside the First Island chain over the South China Sea. Their first acquisition was five unmanned F-16s from Beale AFB. One by one, these automatically signed in with the arsenal craft, exchanged status, mission, and sensor data, and fell into an aerodynamic flight profile.
The F-16s were remanufactured. Each was augmented with an upgraded multifunction AESA radar, additional C3ISR sensors and transceivers, and offensive and defensive countermeasures of various types and capabilities. The wings were lengthened and shaped for extended range, greater strength, and enhanced stealth. New low maintenance coatings further reduced their cross-section.
In order to increase the F-16s’endurance, high-capacity conformal fuel tanks were added. These blended with the wings and fuselage, added above wing recessed weapons stations, and were fully integrated into the in-flight refueling capability. Also, the F-16s were reengined with fuel-efficient ones identical to those of Cole’s plane.
On-board an America class LHA stationed in the eastern Pacific, V/STOL refueling drones were loaded with extra drop tanks by four exoskeleton assisted sailors. The sailors loaded full tanks on all seven. Deck handlers, using remote operator packs, stewarded the drones around the deck. Another two sailors topped off the drones using a robotic refueling station. The on-deck operation looked like an Indy car pit stop.
Five drones lifted off with full loads for the F-16s. Two other larger drones would service the arsenal craft that Cole and Work piloted. The drones hailed the strike flight mission controller on board the B-42 and negotiated pairings, speeds, and altitudes. As they deployed their refueling drogues, an exchange of terahertz correlating signals autonomously guided the drones’ baskets and flight members probes to positive connections. After transferring full fuel loads, the drones dropped out of formation and the flight resumed cruise speed and altitudes.
Major Cole reviewed the entire procedure via a graphical display that signified each stage of the evolution. The unified display was projected into his eyes from emitters around the cockpit. Wherever he looked he saw the air picture around him, the running mission itinerary in the lower foreground, and labelled procedure steps associated with each F-16 and their red, yellow, or green status.
The imagery and text were sharp and stable. He needed no heavy helmet to see this holographic display. Cole thought the sunset beamed in from the fuselage cameras was beautiful this evening.
As he looked down toward the sea surface he could make out a container ship. AIS indications hovering over the IR enhanced, ship image said it was the Pacific Conveyor headed towards California. He increased magnification by stretching it with his two index fingers. The gloves he wore gave a reassuring force feedback.
He could also fly the B-42 using those gloves. They gave feedback like that of a HOTAS and his boots gave him rudder control. If need be, he could take command using only his voice. However, except for takeoff and landing, and that, only for proficiency, the B-42 mission controller did the flying.
The arsenal craft’s onboard server farm was connected with CONUS via several multispectral, encrypted, LPI channels to verify mission integrity, monitor system health, and exchange bulk C3ISR data. The craft’s infrastructure executive performed reconfigurations autonomously to maintain a specified one year MTBF. The mission executive always informed Cole of system status. He was rarely asked to intervene in decisions it made.
When the tactical situation required beyond-human speed and accuracy, the craft presented opportunities to intervene using timed aborts. The mission executive acted automatically when the countdown expired. This kept Cole’s workload down if they were under attack or in other emergencies.
As they approached the Hawaiian Islands (a contested American possession of the recently claimed Third Island chain), the B-42 woke Captain Work. Cole then reviewed with her what had happened while she slept and initiated his own sleep cycle. The integrated pilot’s position provided situation awareness via the holographic display, health and wellness monitoring and restoration, and a self-enclosing escape module.
The craft could put you asleep, wake you up, heal minor wounds, or expel you when necessary for your survival. Captain Work sometimes felt superfluous during long missions, especially because of the last of the craft’s capabilities. She wondered why they couldn’t do these missions telerobotically. Her father recently asked: “How can you be promoted when you command a bunch of robots?”
Mission parameters had changed during their transit. They’d pick up a sixth autonomous F-16 over Joint Base Pearl Harbor-Hickam. This one was optimized for supersonic combat and had a few tricks up its sleeve. Their next refueling would occur south of Yokota Air Base half way between Japan and the Philippines and the First and Second Island chains. They’d also pick up some refueling drones.
Computer aided operators at the monitoring station responsible for the ocean-observatory covering the Southwest Pacific had tracked the SSBNs. All three Type 096 Tang class ballistic missile submarines egressed from Hainan Island into the South China Sea. Two were trailed by our attack boats and knew it. Their commanders expected to be sunk if they opened their missile hatches or torpedo doors.
The third sub was acquired by two Sea Hunter class ASW Continuous Trail Unmanned Vessels. Supervisors ashore used ocean observatory data to re-vector these if necessary. Though usually employed against inexpensive Diesel-Electric boats, ACTUV was deemed the best asset to participate in this mission. This submarine was commanded by the son of one of the participants at the Geneva talks.
Initially, the PRC boomer tried to shake the first Sea Hunter by navigating under fishing fleets and through other heavy shipping traffic. The ACTUVs autonomously navigated according to COLREGS and passed safely by the obstacles. The Type 096 captain settled into a pattern at depth and speed compatible with their communications buoy. The ACTUVs did not lose it during the wait. Eventually, two more Sea Hunter class boats would join the overwatch.
The Sea Hunters tag teamed the Tang class submarine, ever watchful for a break in its pattern. It was possible it could make a dash for deeper waters after receiving orders. However, the observatory would pick that up. In any case, it would have to return to launch depth and these or some other Sea Hunters or an attack boat would be vectored to reacquire it. Such TTPs gave submarine captains pause. The supervisors in Hawaii continued to monitor the Sea Hunters’ health and operations.
As the strike flight approached the First Island chain, drones ascended from an LHD attached to Sea Base Charlie stationed west off Luzon. Captain Work watched as the drones integrated with her flight. Her foreground itinerary indicated several mission updates were passed from the drones to the arsenal craft via near-field-communications.
One update was a message from the President of the United States. She carefully listened and flagged it for Cole’s debrief package. After refueling, all but three, long-range drones returned to Sea Base. These attached to the flight to top off the constituents tanks when they set up orbit over their target.
The craft wakened Major Cole before the flight was scheduled to enter orbit around their moving target. Once the effects wore off, and they did fairly rapidly, Captain Work briefed him. What each saw in their respective fields of view were tailored for their roles and reflected personal customizations. Cole’s eyes opened wide as he listened to the President’s orders. He could not remember anything similar except from a scene in the 60’s movie Fail-safe.
The arsenal craft exchanged encrypted messages with the Sea Hunters as it approached the OPAREA. The craft would orbit at its maximum cruising altitude with the F-16s and refueling drones distributed above and below its position. The orbit had a radius of over 50 miles centered on the Sea Hunters that were trailing the Tang class SSBN. Depending on nearness, all intra-flight communications used either laser or submillimeter microwaves. These channels employed corresponding photorefractive or active retroreflective transceivers to reduce sidelobe interception and jamming.
The B-42 had been monitoring signals traffic, radar probes, and assorted other intercepts. The F-16s sent target and intercept signatures derived from their apertures to the B-42. The arsenal craft’s mission executive relayed to CONUS several new modulations that the discrimination engine identified as missing from its up-to-date database. The electronic attack module was in the process of synthesizing countermeasures for them. Both would be disseminated worldwide. The mission executive used burst transmissions to comms satellites overhead and continued to look for new signals.
Space Command had launched a constellation of nano-satellites in the days following the PRC’s destruction of some of our Defense Communications satellites. Enough satellites were taken out to cause significant coverage gaps over the Pacific during a 24 period.
A combination of contracted commercial and dedicated military launches filled those gaps in nine days. The networked, medium longevity CubeSats provided full-spectrum communications. Neither the Geostationary nor Lagrange Point satellites were affected in these attacks. However, chip-scale positioning, navigation, and timing liberated US forces from unreliable dependencies.
One of the F-16 AESA radars, in synthetic aperture mode, first detected the raid. Twelve Chengdu J-20 long-range, air-superiority fighters were headed in. Their radars would not detect the strike flight for minutes.
The arsenal craft proposed several alternative battle plans to Cole and Work. After Cole selected one of the plans, the mission controller repositioned the flight components to best achieve mission success. Cole liked the plan he picked because of the wide variety of alternative actions it offered. All the flight components were below sound speed so IRST sensor range would favor them during closure.
The mission executive aboard the arsenal craft coordinated the selected plan with the F-16s. Two of these each fired several extended range missiles and two escort decoys. The decoys broadcasted jamming signals which appeared to emanate from PL-21s, PLAN’s own long-range missiles.
These jamming signals illuminated three of the approaching fighters sufficiently for our extended range missiles to lock on and destroy their targets. The US missiles and jammers were communicating between themselves to apportion the targets they would strike. The missiles also relied secondarily on IR to in addition to PRF jittering and FH to prevent target pull-off. Onboard data fusion gave them the best candidates. The decoys impacted two more J-20s.
The B-42 used radar and IR data from the outlying F-16s and returns off the J-20s from the decoys plus the J-20s own signals to refine fire control solutions it disseminated back to the F-16s. The B-42 directed more missile and decoy salvos from the F-16s to interdict the raid before the Chengdus could acquire the arsenal craft. Almost two-thirds of the enemy raid was destroyed before the first return fire salvo was committed.
The F-16s launched decoys that simulated hundreds of B-42 and F-16 skin reflections and signal emissions for the minutes the enemy missiles were airborne. Three of those missiles were seduced into striking the decoys. The dance of chaff around the strike flight was mesmerizing. Those missiles that endured passed the arsenal craft and fell, expended, into the sea. The remaining five Chengdu fighters continued to close.
Electroluminescent panels on the F-16s and the arsenal craft blended them into the background. Each of the flight components began heat signature abatement by running fuel under their fuselage skins. Two more J-20 fighters were splashed before they could launch their PL-21s. The three remaining closed in for the kill with short-range missiles. The subsonic F-16s were running out of weapons.
By now, the F-16s had expended over three-quarters of their radar decoys. This time they employed IR ones; heat signatures were everywhere. The enemy’s ripple fired, short-range, IR missiles scattered. Only two found their marks in a subsonic F-16 and a tanker drone. When the three Chengdu fighters had launched their IR salvo, their RWRs indicated a flight of four supersonic F-22s were descending on their position.
With seconds to decide, they turned and ran. The decoys emitting F-22 and AMRAAM missile signals pursued the Chengdus out of the area. Previously, the supersonic F-16 had flown up to its maximum ceiling above intermittent cloud cover and waited until the mission plan called for its decoy intervention. It too, had suppressed it’s thermal and visible signatures and had maintained subsonic flight.
A new raid was inevitable. Cole and Work waited pensively for word on their mission goal. The mission executive informed them that real F-22s and F-35s were on their way now from forward expeditionary bases to provide CAP. They could not arrive soon enough.
The mission executive cued Cole to a priority message from STRATCOM. They got the “go code.” That meant that talks had failed and an SSBN launch was imminent. Major Cole entered his identification number and Captain Work followed within five seconds.
The mission executive verified with the Sea Hunters that they had lock on the Tang class SSBN. The doctrine module identified to the executive an impact point astern of the SSBN’s sail. The arsenal craft’s fire control module computed the trajectory, verified and validated it, and down loaded it to the two rocket-propelled torpedoes. These weren’t torpedoes in the usual sense, though.
The mission executive actuated the bomb bay doors. Immediately, Cole and Work heard an alarm and saw flashing notices that the doors would not open. The mission executive was asking for permission to jettison the doors entirely. It almost never made an untimed request for intervention. However, because the craft’s stealth signature would be gravely compromised jeopardizing both the mission and, possibly, their lives, the executive waited.
Cole knew this was no “Major Kong” moment and elected to jettison the doors. There was no way to reach the bomb bay in any case. That CAP had better be snappy, Captain Work thought. Word went out to STRATCOM from the mission executive of their situation. Confirmation appeared on the pilots’ itineraries.
One torpedo fell away. When it was clear of the craft, the rocket motor ignited and it plunged to the sea surface. Right then, the Sea Hunters relayed to the B-42’s mission executive that the SSBN hatches started to open. A synthesized image of the SSBN was visible to both pilots off the B-42’s port side. Cole and Work saw status updates as they occurred. Iconography indicated the projected torpedo aim point behind the sail and ahead of the opening hatches.
As the torpedo’s tungsten nose tip entered the water, rocket exhaust exited from its nose manifold. The exhaust created a cavitation sheath that enabled the torpedo to penetrate the water to strike the submarine. Terminal guidance directed it using water contacting fins and exhaust manifold redirection. It breached the hull, exploded, and the submarine sank without launching its missiles.
The remaining Sea Hunter declared a sub kill to the arsenal craft based on active and passive sonar signals. Additionally, Sea Hunter surface search radar picked up many new obstacles to maneuver around. F-16 GMTI data showed debris on the water surface consistent with a submarine kill. The mission executive’s threat assessment module informed both the pilots and STRATCOM of the success. Major Cole and Captain Work were relieved.
Immediately, a different alarm sounded. The mission executive identified a second raid at beyond-visual-range. Try as they might, neither pilot could see them below their icons. With their stealth compromised, four remaining subsonic F-16s low on weapons and decoys, the supersonic F-16, and two tanker drones, they were not sure what the mission executive would suggest.
Work’s jaw dropped when she saw the plan. Cole approved it and tightened his seat harness belts and tie down strap. Captain Work followed his lead.
Four J-20s carried missiles on all their external weapons stations. They would not be spooked by decoys this time. They knew what to expect. On cue, two F-22s and four AMRAAMs registered on the J-20 warning receivers. They did not veer off their intended target, the United States B-42 arsenal craft and the unmanned F-16s.
The Chengdu pilots launched a mix of PL-12s and PL-10s. The F-16s fired their missiles in return and released their remaining short-term decoys, a mix of IR and radar seducers. The F-16s interposed themselves into the enemy missile paths that would otherwise strike the B-42. Simultaneously, the F-16s AESA radars emitted jamming signals to disrupt the incoming, enemy missiles and prevent further targeting.
All four F-16s were destroyed. Of the four Chengdus, one remained. This pilot was golden, all of the B-42’s air cover was eliminated. He was the lone avenger of his fallen comrades. But where was the B-42?
In the melee, the IR seduction decoys led all the PL-10s toward the two refueling drones. The drones had ignited fuel spewing from their retracted drogues and were lit up like torches. The IR missiles struck the two drones causing a tremendous fireball. The B-42 had dived through the fireball and down like a rock to the sea surface. The mission executive then initiated the next phase of the plan.
As the PLAAF pilot half-rolled his aircraft to invert it he could see the B-42’s electroluminescent camouflage panels flickering below. This was an easy kill with two PL-12s, he thought. The pilot continued his descending half-loop headed for the B-42 far below. He’d have lock on the B-42 before his maneuver’s exit.
What the pilot didn’t realize was the coordination between the B-42 and supersonic F-16 that was now descending out of high clouds. The F-16 targeted the J-20’s underbelly with two missiles. Before the J-20 could descend half way, the AMRAAMs struck. One clipped a wing but the other penetrated the fuselage and exploded. The J-20’s bulk and fire-retardant design gained its pilot the seconds needed to eject.
The B-42 panels resumed a consistent glow blending the arsenal craft with the sea surface. The supersonic F-16 joined it to provide protection. Two minutes later, the B-42 and F-16 rose up to meet two F-35s and an F-22 that escorted them to Antonio Bautista Air Base.
Acronyms
| ACTUV |
ASW Continuous Trail Unmanned Vessel |
| AESA |
Active Electronically Scanned Array |
| AFB |
Air Force base |
| AIS |
Automatic Identification System |
| AMRAAM |
Advanced Medium-Range Air-to-Air Missile |
| ASW |
Anti-Submarine Warfare |
| B |
US Bomber designation |
| CAP |
Combat Air Patrol |
| C3ISR |
Command, Control, Communication, Intelligence, Surveillance and Reconnaissance |
| COLREGS |
Convention on the International Regulations for Preventing Collisions at Sea |
| CONUS |
Continental United States |
| F |
US Fighter designation |
| FH |
Frequency hopping |
| GTMI |
Ground Target Moving Indicator |
| HOTAS |
Hands On Throttle-And-Stick |
| ISRT |
Intelligence, Surveillance, Reconnaissance, and Targeting |
| J |
PRC Fighter designation |
| LHA |
Landing Helicopter Assault |
| LHD |
Landing Helicopter Dock |
| LPI |
Low Probability of Intercept |
| MTBF |
Mean Time Between Failures |
| OPAREA |
Operating Area |
| PL |
PRC Missile Designation |
| PL-10 |
PRC short range, IR guided missile similar to AIM-9X Sidewinder |
| PL-12 |
PRC medium range, radar guided missile similar to AMRAAM |
| PL-21 |
PRC long range, radar guided missile similar to MBDA Mica or Aster |
| PLAAF |
People’s Liberation Army Air Force |
| PLAN |
People’s Liberation Army Navy |
| PRC |
People’s Republic of China |
| PRF |
Pulse Repetition Frequency |
| RWR |
Radar Warning Receiver |
| SAR |
Synthetic Aperture Radar |
| SSBN |
Strategic Submarine Ballistic Nuclear |
| STRATCOM |
Strategic Command |
| TTP |
Tactics, Techniques, and Procedures |
| US |
United States |
| V/STOL |
Vertical and/or Short Take-Off and Landing |